
Introduction
I’m currently blogging about a series of DEM in 20 webinars from 1E, you can find each episode that I’ve blogged about (including this one) below:
- Episode 1. How to find and fix Slow Endpoints
- Episode 2. That crashy app
- Episode 3. Dealing with annoying admin requests
- Episode 4. That Change Management Success Rate Struggle <- you are here
- Episode 5. Will Printer Audits continue to exist?
- Episode 6. Are non compliant devices dangerous ?
If you haven’t already noticed I’m currently blogging about a series of DEM in 20 webinars from 1E and I’ve linked each one that I’ve covered below for your perusal. In today’s blog post I’ll focus on how to deal with that Change Management Success Rate Struggle.
That’s a mouthful, but in a nutshell what it means is how can you cope with the onslaught of issues raised both pre and post change for a change management request.
Every company has to deal with change management, possibly even more so now with so many people still working from home. Not only will you learn how to deal with the change management success rate, but get real time data before and after the change.
Why is change control important ?
Help Desk International (HDI) referenced that 80% of incidents are caused by internal change. That’s a huge percentage.
“80% of incidents are caused by internal change”
If we could just control that better and get an idea of what the output would be like before we roll it out into production then we’d have less incidents and more time to do the job we we’re hired to do.
Change Control Requests
Change control usually starts with a change control request form for the desired change, in this example it’s for a global Zoom upgrade. Zoom is telecommunication software for holding meetings, and it became hugely popular during the ongoing Covid pandemic due to so many workers having to work from home.
As new features are added, or security patches released, new versions need to be pushed out, and that all starts with a change control request.
 In Robs’ line of business (Rob Key, Senior Solutions Engineer at 1E), and some of the customers he talks to, it’s common to see them using the following methods for change control, either by sending the change to IT so they can test it on one or more machines, and then after doing that test, sending out a survey to the users involved asking how did that affect your machine, but depending on that change, IT might not dig in as deep as we’d like or using an UAT (user acceptance testing) group to look at it.
In Robs’ line of business (Rob Key, Senior Solutions Engineer at 1E), and some of the customers he talks to, it’s common to see them using the following methods for change control, either by sending the change to IT so they can test it on one or more machines, and then after doing that test, sending out a survey to the users involved asking how did that affect your machine, but depending on that change, IT might not dig in as deep as we’d like or using an UAT (user acceptance testing) group to look at it.
Capturing pre-change data
Let’s take a different approach using Tachyon Experience. Not only can we do monitoring but we can check health and compliance policies on a group of test machines to make sure that we can see that those machines stay healthy both before and after the change is completed.
For that we’d want to capture pre-change health and compliance information. In this particular example there are two control groups, manufacturing and marketing.
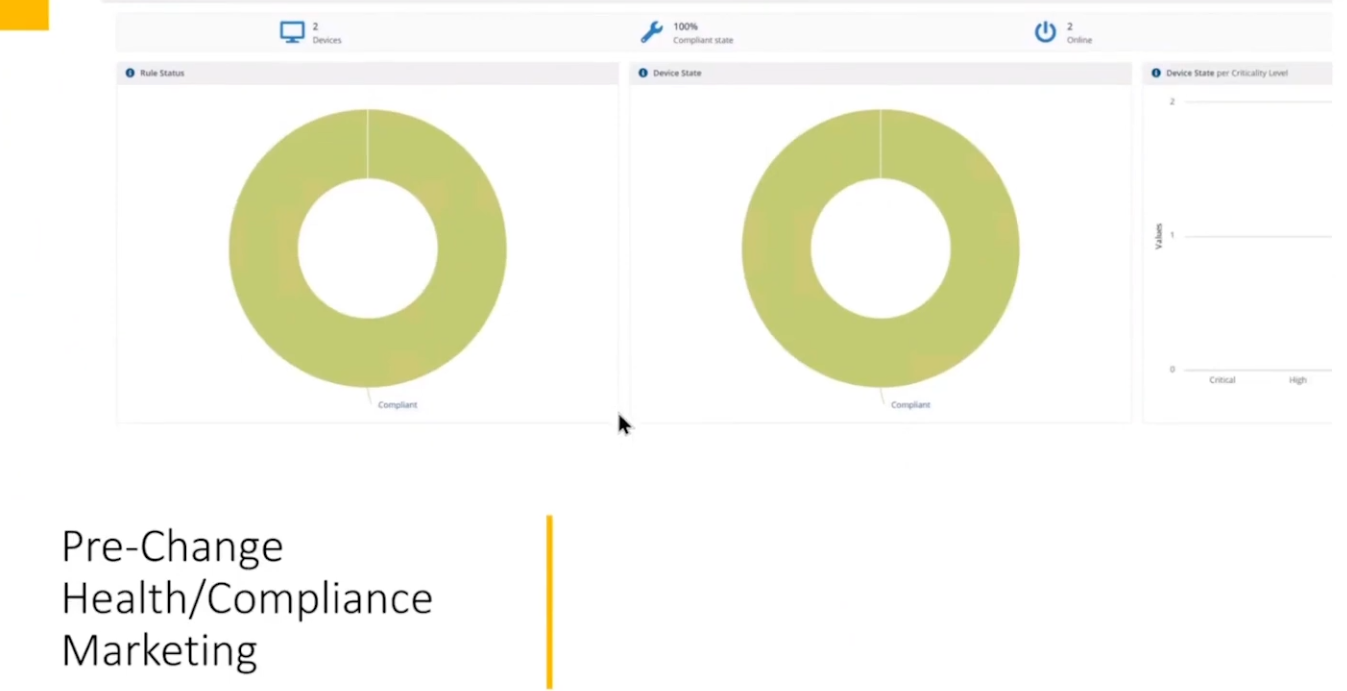
These are two different parts of the organization and they have different needs, so they should be good target groups for the data that we need.
In the screenshot below we can dig down and see that services are healthy and all of the numbers are looking good.
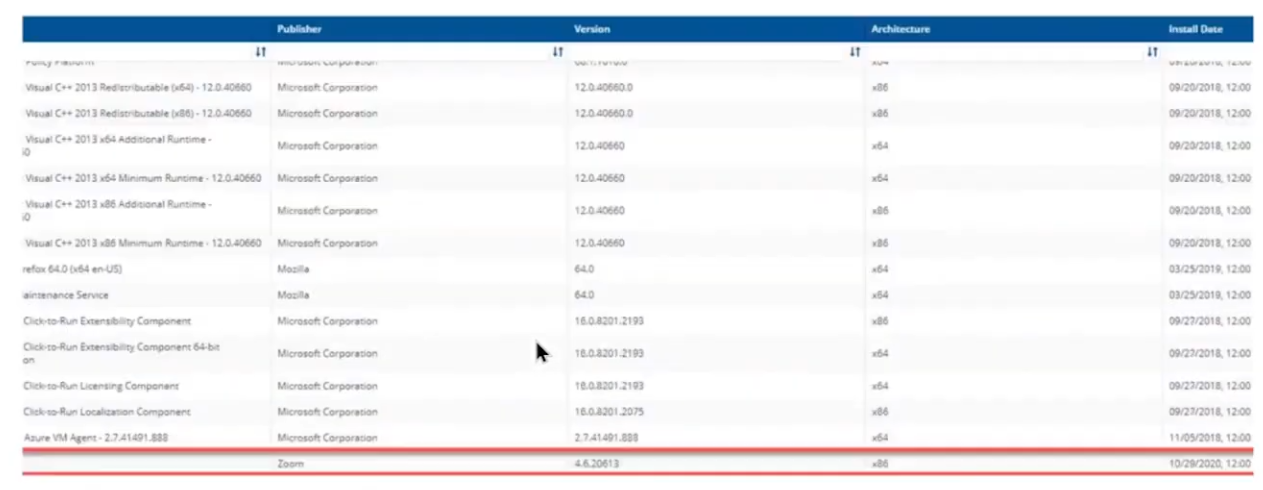
 Next we can verify the version (in real-time) of the target software we intend to change, and below we can see it’s not yet upgraded.
Next we can verify the version (in real-time) of the target software we intend to change, and below we can see it’s not yet upgraded.
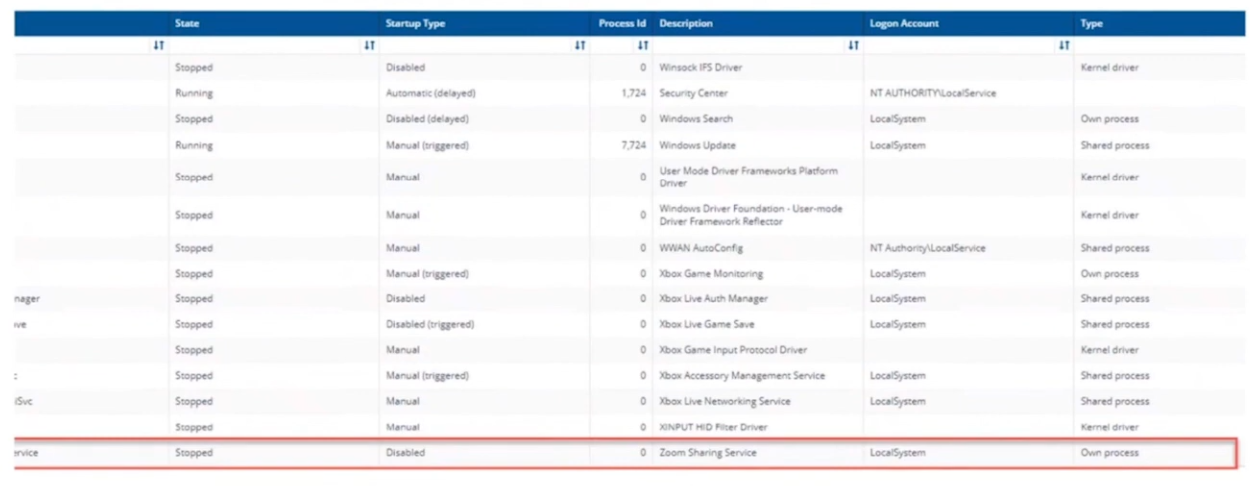
 We can also see the services running, or in the example below, that a Zoom sharing Service is both stopped and disabled. It was disabled as a policy was created to not allow that service to run in the manufacturing group, for security reasons, to stop the release of important and confidential information. For the marketing group another policy was created to allow it to run.
We can also see the services running, or in the example below, that a Zoom sharing Service is both stopped and disabled. It was disabled as a policy was created to not allow that service to run in the manufacturing group, for security reasons, to stop the release of important and confidential information. For the marketing group another policy was created to allow it to run.
 Post-change rules to guarantee state
Post-change rules to guarantee state
Any area of a business that goes down due to change management processes that go wrong costs that business money, so to avoid that, policies are created in Tachyon in Guaranteed State. You can see two policies in the drop down menu below, one for marketing, and one for the manufacturing group.
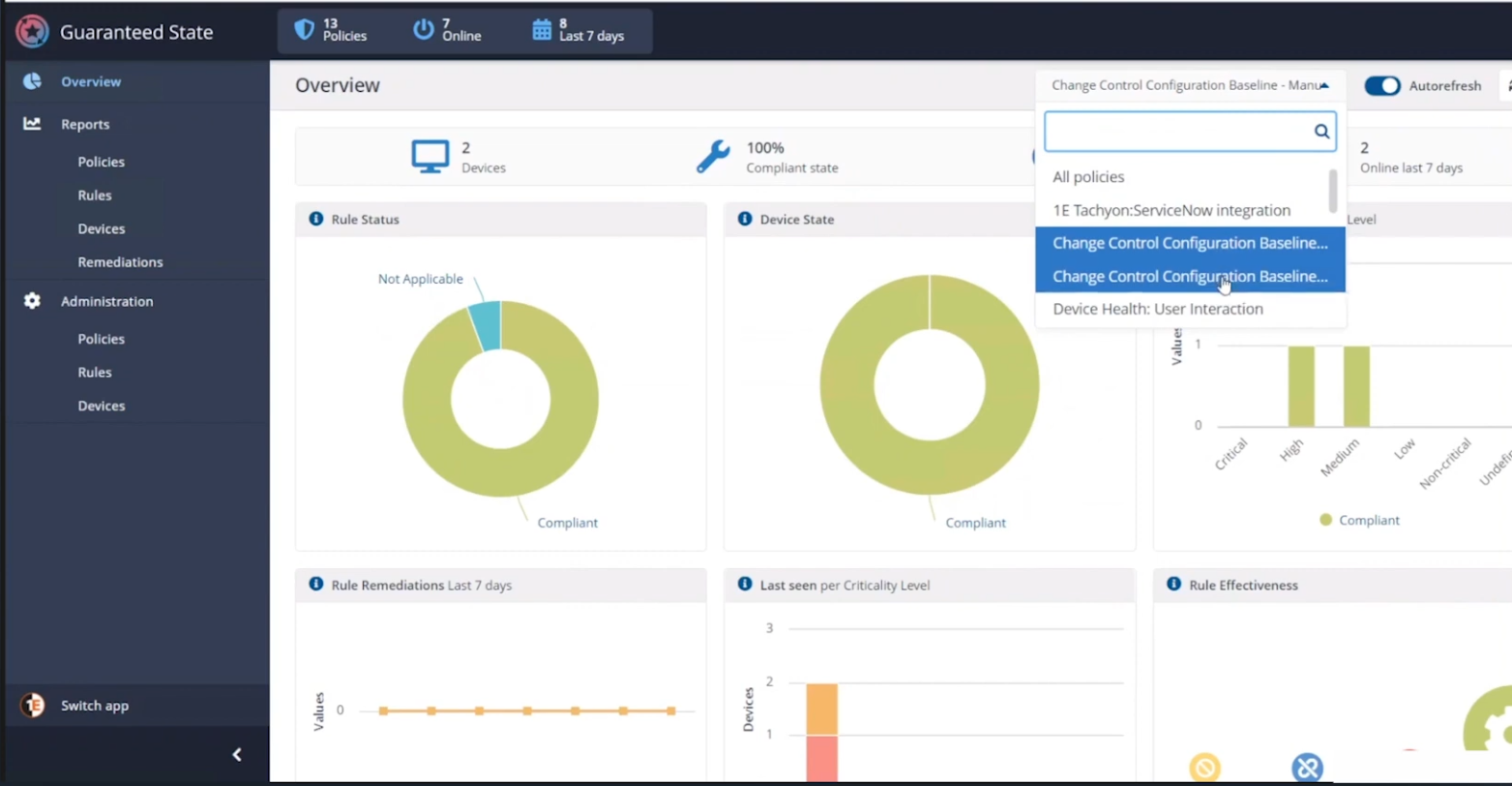 Here’s a closeup of those policies. These policies are created using one or more rules in Tachyon Guaranteed State.
Here’s a closeup of those policies. These policies are created using one or more rules in Tachyon Guaranteed State.

This is post-change, and here we can see a rule from our policy targeting the marketing department, pay attention to the Not Applicable slice.
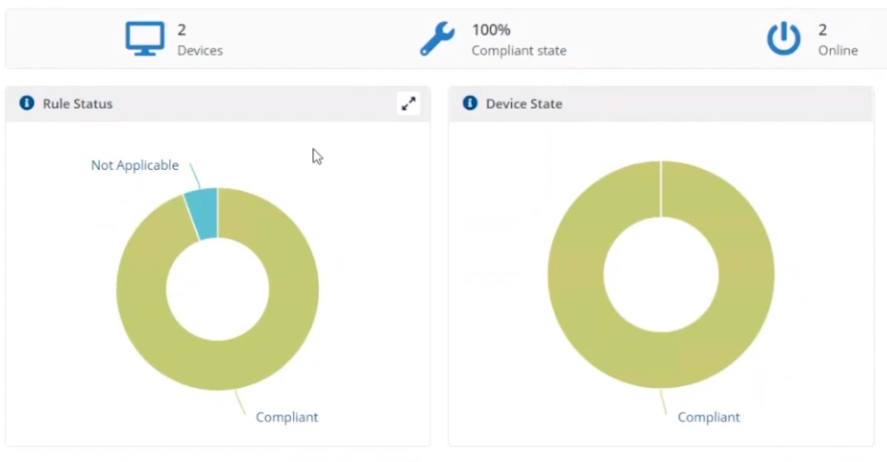 Clicking on that reveals the following, and here we can see that there is a check to ensure that the Zoom sharing service is enabled, however this new version of Zoom doesn’t use this as Zoom changed the way they structure their software.
Clicking on that reveals the following, and here we can see that there is a check to ensure that the Zoom sharing service is enabled, however this new version of Zoom doesn’t use this as Zoom changed the way they structure their software.
 So how were these Guaranteed State policies created?
So how were these Guaranteed State policies created?
Each rule can check for various things, such as checking for free disk space or whether or not the Zoom Sharing Service is enabled or that the 1E Client service is in a correct state. Below you can see a list of some of those rules.
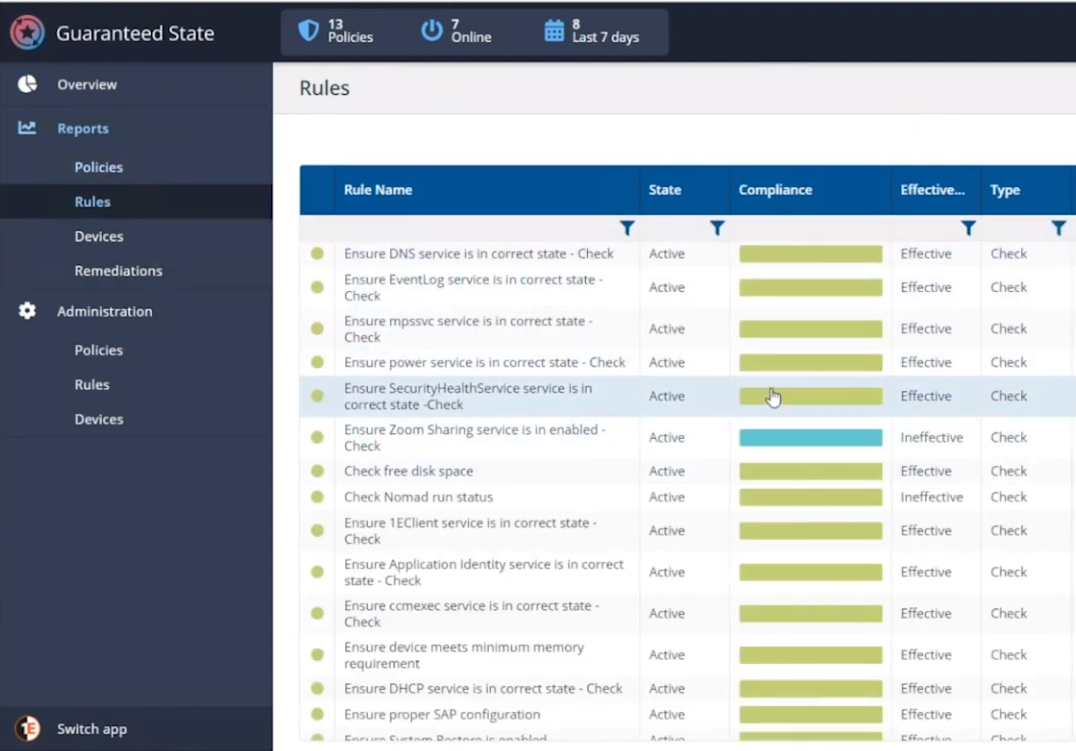
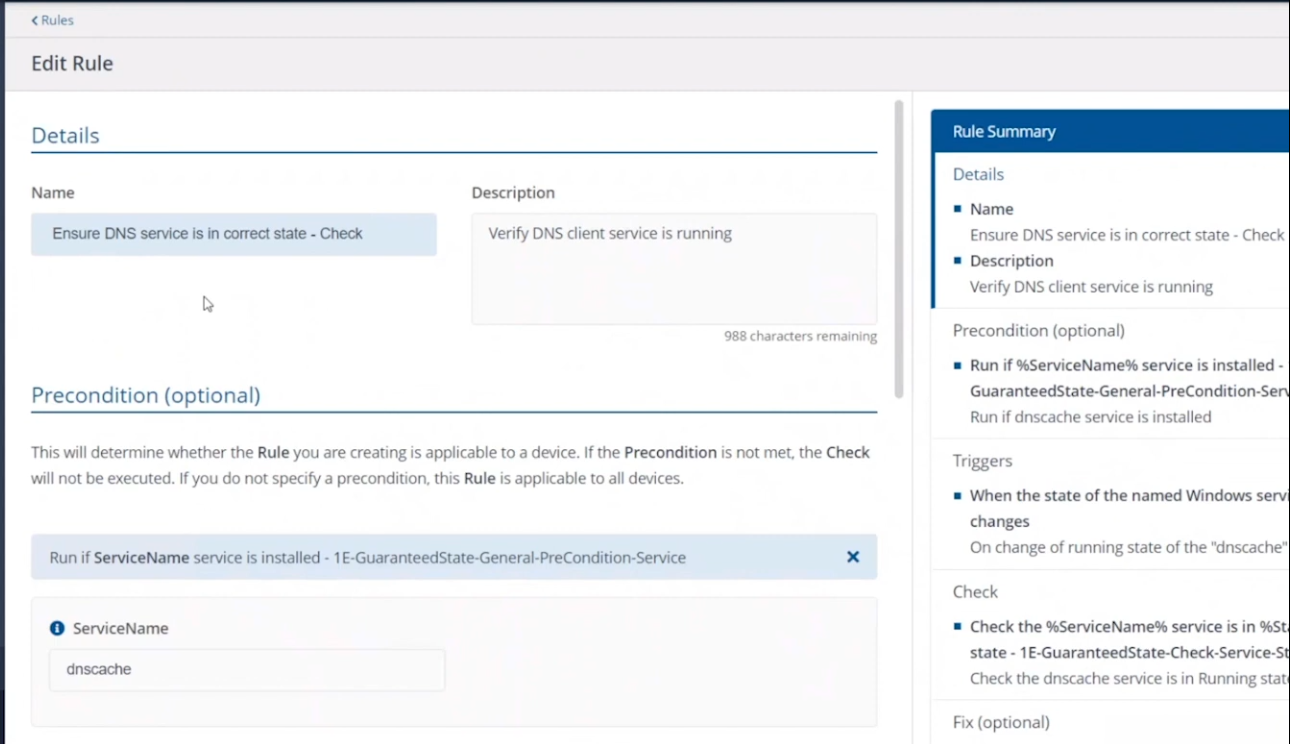
If we take a closer look at a rule, in this case a rule to Ensure the DNS service is in a correct state, you can see from the screenshot below that the rule looks at optional Pre-conditions, Triggers, the Check itself and an optional Fix.
What about non-compliance post-change ?
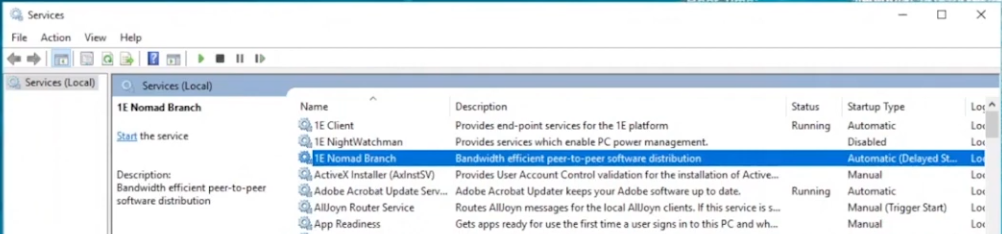
Seeing real-time results that reveal non-compliance post-change is a great ability. That can be revealed by our Guaranteed State policies. To test this, killing a service which is checked for (one of the rules above) reveals this in real-time. Below a service is stopped…
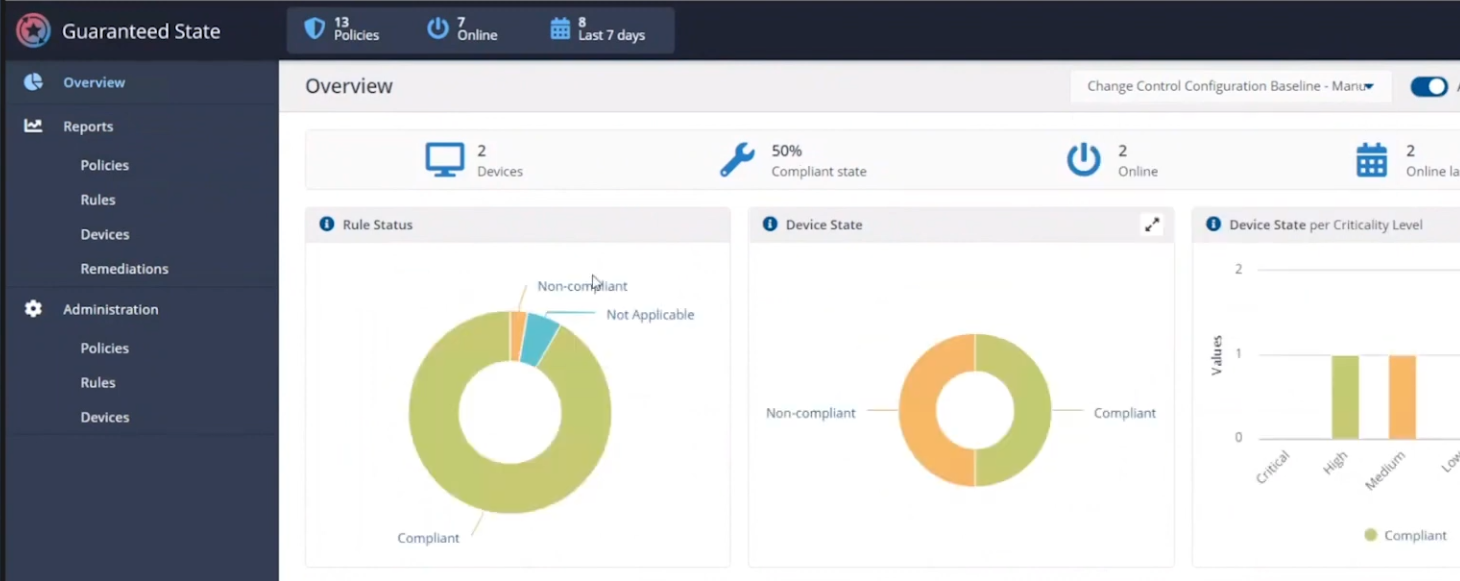
 and reviewing the rules results, you can straight away see that there is non-compliance and drill down to find out more information.
and reviewing the rules results, you can straight away see that there is non-compliance and drill down to find out more information.
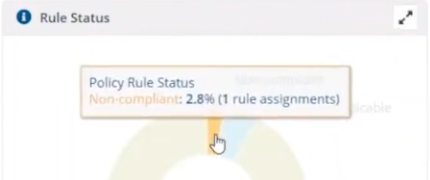
 This is instantaneous, which means you can see how to control the change management process with ease by gathering data and responding effectively.
This is instantaneous, which means you can see how to control the change management process with ease by gathering data and responding effectively.
“So how quick is quick ?”
This really depends on what you are looking at, for example disk space might be polled every minute or 30 seconds. But when you are talking about registry changes or config file changes or services, that is real-time.
Conclusion
Change happens all the time in business and while most companies have their own change management processes to deal with that change, they are very likely contributing to their own workloads by the way they do it. Remember, internal changes that are not correctly monitored pre and post change can cause major problems.
Using Tachyon Experience and Tachyon Guaranteed State gives your admins the power to see those results in real-time and allows them to easily tweak the change management process to increase their success rate.
